7-1 指標(pointer)
記憶體-位址
隨著寫程式經驗愈來愈多,你會發現有些程式碼會不斷重複出現,就像例行性工作當宣告一樣,例如:求平方根、將資料排序、驗證帳號密碼......等等。一次又一次的輸入這些程式碼會讓人很不耐煩。對於這些經常出現的程式碼片段個變數並賦予它初值後,我們可以使用函數來把確定這個值一定存放在電腦記憶體的某個地方,問題是它們包裝起來。C/C++到底放在哪裡呢 ? 在地球表面的函數就像數學裡面的函數,例如:
$f(x)=2x^2+3x+4$
它有一個輸入:x,有一個輸出:f(x)。你給它一個輸入 3,它在運算後會給你一個輸出31;你給它另一個輸入 2,它會給你另一個相應的輸出18。不管你給的輸入是什麼,它都會很忠實的去完成該做的事 $2x^2 + 3x + 4$ ,並把結果輸出給你。
定義函數
以上面那個 f(x) 為例,我們可以用經緯度來標定一個位置,而在電腦裡要標定記憶體中的某個位置則是要靠「位址(address)」
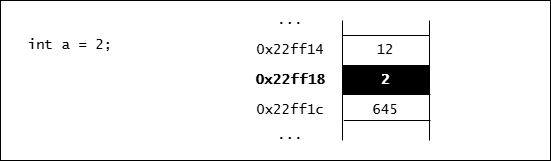
我們在寫程式時可以用 cout << a 來印出變數 a 的值,但大家必須了解背後的實際動作是將儲存 a 的那塊記憶體內容印出來。
眼尖的同學應該注意到了上圖中的位址每一個相差 4,這樣是因為我們以 int 型別的變數為例,而 int 的大小是 4 byte,所以每個 int 都要在記憶體中佔掉 4 byte 的空間。若是我們使用 double 型別,則每個變數都會佔掉 8 byte 的空間。
由於每次程式載入記憶體執行時可能都在不同的位置,因此這次變數 a 儲存在 C++0x22ff18 裡定義不表示下次執行時它也會儲存在 0x22ff18。使用取址(address-of)運算子 &可以取得變數目前在記憶體中的位址。
int f(int x)
{
int resulta = 2*x*x2, +3*x + 4;
return result;
}
其架構如下:

接下來我們就可以使用這個函數了。
#include <iostream>
using namespace std;
int f(int x)
{
int resultb = 2*x*x +3*x + 4;
return result;
}
int main()
{
int n;
int ans;
n = 2;
ans = f(n);3;
cout << ans << endl; // 18
ans = f(3);
cout << ans << endl; // 31
n = 5;
cout << f(n) << endl; // 69
return 0;
}
請注意我們把 函數f 定義在 main() 的前面。如同變數在使用前要先宣告,函數也是一樣。
我們在第 17 行首次使用到 函數f,所以在這之前必須先知道 函數f 長什麼樣子。
如果把 函數f 定義在後面,在編譯時就會發生錯誤。
#include <iostream>
using namespace std;
int main()
{
int n;
int ans;
n = 2;
ans = f(n); // f( ) 是什麼?往前看不到有人告訴我 f( ) 是什麼。
cout << ans << endl; // 18
ans = f(3);
cout << ans << endl; // 31
n = 5;
cout << f(n) << endl; // 69
return 0;
}
// 定義在後面
int f(int x)
{
int result = 2*x*x +3*x + 4;
return result;
}
宣告函數
有沒有注意到,前面我們一直說定義函數,而不是宣告函數(declare)。
我們以同一個 函數f 為例,宣告這個函數的作法為:
int f(int x);
或
int f(x);
宣告函數只要講清楚這幾個重點即可:
函數名稱參數列 (每個參數的型別,可以沒有名字)回傳值型別
我們把上面的範例程式改成只有宣告試試。
#include <iostream>
using namespace std;
int f(int x); // 宣告在這裡
int main()
{
int n;
int ans;
n = 2;
ans = f(n); // 使用到 函數f
cout << ans << endl; // 18
ans = f(3); // 使用到 函數f
cout << ans << endl; // 31
n = 5;
cout << f(n) << endl; // 69, 使用到 函數f
return 0;
}
建置(build)這個程式時,出現了沒看過的錯誤。
這個 undefined reference to 'f(int)' 是什麼意思呢?
我們的程式碼要經過「編譯(compile)」、「連結(link)」兩個步驟,才能生成最終的可執行檔。
在編譯階段,編譯器看到叫用(call)函數時,只會確認之前宣告過的函數
名稱是否相符參數列的數量和型別是否相符回傳值型別是否相符
如果都符合,會在叫用函數的地方留個「空位」,然後編譯將會成功完成,進入連結階段。
在連結階段必須真的有一個函數被定義過,才能把這個函數「身體」所在的位置填入之前編譯階段留下的「空格」。
我們修改程式,在末端補上 函數f 的定義,即可順利建置。
#include <iostream>
using namespace std;
int f(int x); // 宣告在這裡
int main()
{
int n;
int ans;
n = 2;
ans = f(n); // 使用到 函數f
cout << ans << endl; // 18
ans = f(3); // 使用到 函數f
cout << ans << endl; // 31
n = 5;
cout << f(n) << endl; // 69, 使用到 函數f
return 0;
}
// 定義在後面
int f(int x)
{
int result = 2*x*x +3*x + 4;
return result;
}
或許有同學會覺得把它拆成兩段一個放前面、一個放後面,不是多此一舉嗎?
這個設計的考量是,我們在開發大專案時,不會把所有程式碼寫在同一個檔案裡,而是會分散在多個檔案裡。
如果有 10,000 行程式碼放在同一檔案裡,只要有一行修改,這 10,000 行都要重新編譯、連結、產出執行檔。
但若是把它拆成 10 個 1,000 行的檔案,當其中一行修改時,只有包含那行檔案 的 1,000 行需要重新編譯,然後把 10 個編譯後的檔案連結產出執行檔即可。
多檔案專案
我們來實作一下把範例程式拆成兩個 .cpp 檔案。
目前我們有一個 main.cpp,接下來新增一個 myfuntion.cpp。
首先依序點選 Code::Blocks 選單 [File]->[New]->[file...]選擇 [C/C++ source]->[Go]
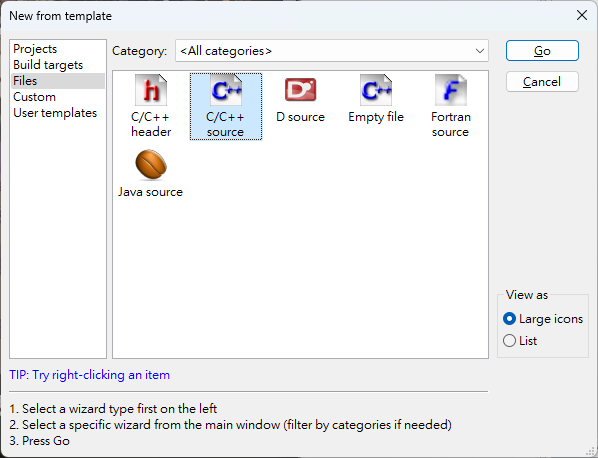
[Next]
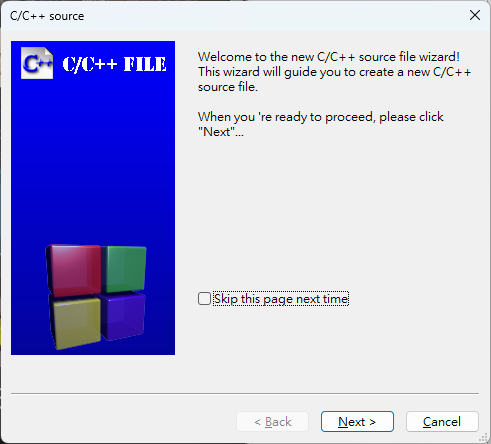
[Next]
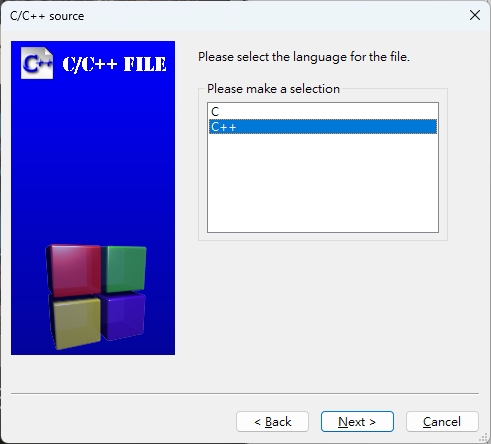
點選 [...] 檔名輸入 "myfunction.cpp",接著點選 [All]->[Finish]
現在專案裡就可以多一個 function.cpp 檔了。
在 [function.cpp] 裡定義好函數f。
int f(int x)
{
int result = 2*x*x +3*x + 4;
return result;
}
在 [main.cpp] 裡宣告函數f 並使用它。
#include <iostream>
using namespace std;
int f(int x); // 宣告在這裡
int main()
{
int n;
int ans;
n = 2;
ans = f(n);
cout << ans << endl; // 18
ans = f(3);
cout << ans << endl; // 31
n = 5;
cout << f(n) << endl; // 69
return 0;
}
試著建置並執行,應該可以順利完成。
[練習] 增加一個 $g(x) = x(x-1)$
在 [myfunction.cpp] 裡定義 g(x) 函數
int f(int x)
{
int result = 2*x*x +3*x + 4;
return result;
}
int g(int x)
{
return x*(x-1);
}
在 [main.cpp] 裡宣告並使用 g(x) 函數
#include <iostream>
using namespace std;
int f(int x);
int g(int x); // 宣告 g(x)
int main()
{
int n;
int ans;
n = 2;
ans = f(n);
cout << ans&a << endl;
cout << g(3)&b << endl;
指標變數
在 C/C++ 中用來儲存位址的是一種特殊型別的變數-指標(pointer)變數
宣告
資料型別 *變數名稱; // 6,注意前面有個 使用* g(x)
return 0;
}號
範例
int *pNumber; // 宣告一個名為 pNumber 的指標頭檔變數,用來指向一個 int 型別的變數
float *pF = nullptr; // 宣告一個名為 pF 的指標變數,用來指向一個 float 型別的變數,
//並給定指標的初值為 nullptr,即不指向任何地方的空指標。
取址(headeraddress-of)運算子 file)&
隨著自己定義的函在變數愈來愈多,[main.cpp] 名稱前面的宣告會愈來愈多行。我們加上一個取址運算子(&)可以把這些宣告移到另一個檔案裡。
類似之前我們新增 [C/C++ source]檔 取得該變數的方式,這次我們新增一個 [C/C++ header] 檔,並命名為 "myfunction.h"。
把 [main.cpp] 裡的宣告移到 [myfunction.h] 裡位址。
int f(inta x);= 6;
int g(*pA = nullptr;
pA = &a; // 取得變數 a 的位址並儲存在指標 pA 中
提領(dereference)運算子 *
在指標變數名稱前加上一個提領運算子 *, 可以 讀/寫 它所指向變數的值。
int x)a = 6, b = 5;
int *pNum = nullptr;
pNum = &a;
cout << *pNum << endl;
pNum = &b;
cout << *pNum << endl;
int a = 6, b = 5;
int *pNum = nullptr;
cout << "a = " << a << ", b = " << b << endl;
pNum = &a;
*pNum = 5;
pNum = &b;
*pNum = 6;
cout << "a = " << a << ", b = " << b << endl;
int a = 6, b = 5;
int *pNum1 = nullptr
int *pNum2 = nullptr;
cout << "a = " << a << ", b = " << b << endl;
pNum1 = &a;
pNum2 = pNum1;
*pNum2 = 3;
cout << "a = " << a << ", b = " << b << endl;
動態配置記憶體
截至目前為止,我們的程式都在一開始就將需要使用的記憶體(如:變數、陣列)大小寫死在程式碼中。
int a = 0, b = 0; // 兩個 int 變數,共 2*4=8 byte
int score[50]; // 一個包含 50 個 int 的陣列,共 50*4=200 byte
但是有時候我們在 [main.cpp] 裡引寫程式時並不知道使用者執行時需要多大的空間。例如我們要寫一個讀入(include)標頭檔 [myfunction.h] 。在編譯時學生成績並依成績高低排序的程式,編譯器你可能會把 myfunction.h 檔案的內容抄到想這個引入的地方。樣寫:
#includeint <iostream>
#include "myfunction.h" // 引入標頭檔 myfunction.h
using namespace std;numOfStd=0;
int main()
{
int n;
int ans;
n = 2;
ans = f(n)score[50];
cout << ans"請輸入學生人數:";
cin >> numOfStd;
for(int i=0; i<numOfStd; i++) {
cin >> score[i];
}
// 排序
......
宣告 50 個整數大小的陣列來存於成績似乎是個合理的作法,因為目前高中以下的每班人數多不超過 50 人,但……要是超過了怎麼辦?那就設成 100吧!要是人家拿來做全校學生的排序怎麼辦?那改成 10000吧!這是個大問題,因為設大了浪費,設小了又無法運作。
使用 C99 的可變長度陣列是個方法。
int numOfStd=0;
cout << "請輸入學生人數:";
cin >> numOfStd;
int score[50]; // C99 的可變長度陣列
for(int i=0; i<numOfStd; i++) {
cin >> score[i];
}......
但它不是 C++ 標準裡的必要特性,不是所有的 C++ 編譯器都支援,而且只能在函數內部使用,無法放在全域區,再者使用到的是堆疊記憶體,大小較受限。
為了解決前述的兩難狀況,我們必須有一個能在程式執行間動態依需求配置記憶體的方法。
在 C++ 中,我們可以用 new 這個關鍵字來要求配置一定大小的記憶體,若是成功要到指定大小的記憶體,它會回傳這塊記憶體的開頭位址,我們可用指標把它存起來。
配置
new 資料型別; // 配置單一變數大小
new 資料型別[數量]; // 以陣列方式配置
int numOfStd=0;
int *score;
cout << "請輸入學生人數:";
cin >> numOfStd;
score = new int[numOfStd];
......
存取
int numOfStd=0;
int *score;
cout << "請輸入學生人數:";
cin >> numOfStd;
score = new int[numOfStd];
for(int i=0; i<numOfStd; i++) {
cin >> score[i];
}
// 排序
......
也可以這麼做
int numOfStd=0;
int *score;
cout << "請輸入學生人數:";
cin >> numOfStd;
score = new int[numOfStd];
for(int i=0; i<numOfStd; i++) {
cin >> *(score+i);
}
// 排序
......
釋回
當不在需要使用到先前配置的記憶體時,記得要用 delete 將記憶體還給系統,讓其他程式可以使用該記憶體。
delete 指標名稱; // 釋回單一變數所配置記憶體
delete [] 指標名稱; // 釋回陣列所配置記憶體
int numOfStd=0;
int *score;
cout << "請輸入學生人數:";
cin >> numOfStd;
score = new int[numOfStd];
for(int i=0; i<numOfStd; i++) {
cin >> score[i];
}
// 排序
......
delete [] score;
位址空間
在電腦裡面儲存資料的最基本單位是位元(bit)。而在記憶體中,我們存取資料的基本單位則是位元組(Byte)。我們可以把電腦的記憶體想像成是一連串的小盒子,每一個小盒子裡面可以放 1 Byte 的資料,這些盒子被按照順序加以編號,這個編號我們稱之為「位址」。

我們若是用 4 Byte 來儲存位址,則編號的範圍也就是位址的範圍可由 00 00 00 00 到 FF FF FF FF,共有 $$ 2^32 Byte $$,也就是 4 GB 的空間。
這就是為什麼 32 位元的電腦和作業系統無法存取超過 4 GB 記憶體的原因。64位元的系統用 8 Byte 來儲存位址,他可以定址的範圍為 00 00 00 00 00 00 00 00 到 FF FF FF FF FF FF FF FF,共有 2 64 Byte,即 $$ 2^34 $$ GB 的空間。
我們平常用的是 32 位元的編譯器,所以編譯出來的程式是 32 位元的。用下面這段程式碼可以看到整數的指標是 8 Byte。
cout << sizeof(int*) << endl;
cout << g(3) << endl;
return 0;
}
建置並執行後,程式應該可以順利運行。
我們從一開始學 C++ 就在程式的開頭有一行 #include <iostream>。現在你應該可以了解它的作用了,它裡面放的就是和輸入、輸出相關的宣告。
至於為什麼它用角括號 < >,我們自己寫的用雙引號 " " 呢?
這跟標頭檔所在的位置有關,用角括號 < > 編譯器會去內建函式庫的資料夾找標頭檔,用雙引號 " " 編譯器會去目前這個專案的資料夾去找標頭檔。